Stateful Stream Processing
Stateful Stream-Processing for Deep Introspection
Live systems generate streams of incoming events that need to be tracked, correlated, and analyzed to identify patterns and trends — and then generate immediate feedback and alerts to steer operations.
With today’s ever more complex real-time systems, it’s not enough to just analyze patterns within data streams using conventional techniques. Applications need deeper introspection to extract full value from the telemetry they receive. They need to build dynamic models of data sources that they can continuously update and analyze. Called stateful stream-processing and popularized as the “digital twin” by Gartner, this breakthrough approach can harness machine learning, neural networks, and other advanced techniques to enable deep introspection and provide precise, timely feedback for live systems.
To illustrate the power of stateful stream-processing with ScaleOut StreamServer’s architecture, consider a heart-rate monitoring application which receives telemetry from wearable devices. ScaleOut StreamServer can route millions of incoming events to dynamic, in-memory components called “real-time digital twins” which track each patient’s unique medical history and current condition, analyzing events and generating timely alerts to medical professionals when needed. Unlike traditional, “stateless” stream processing, which just examines aggregated incoming telemetry as it arrives, ScaleOut StateServer separately analyzes telemetry for each data source in the context its unique state information. In the medical monitoring example, this state information could include medical history, current medications, recent medical events, patient activity, and much more. The result is deeper introspection and more timely, effective feedback and alerting.
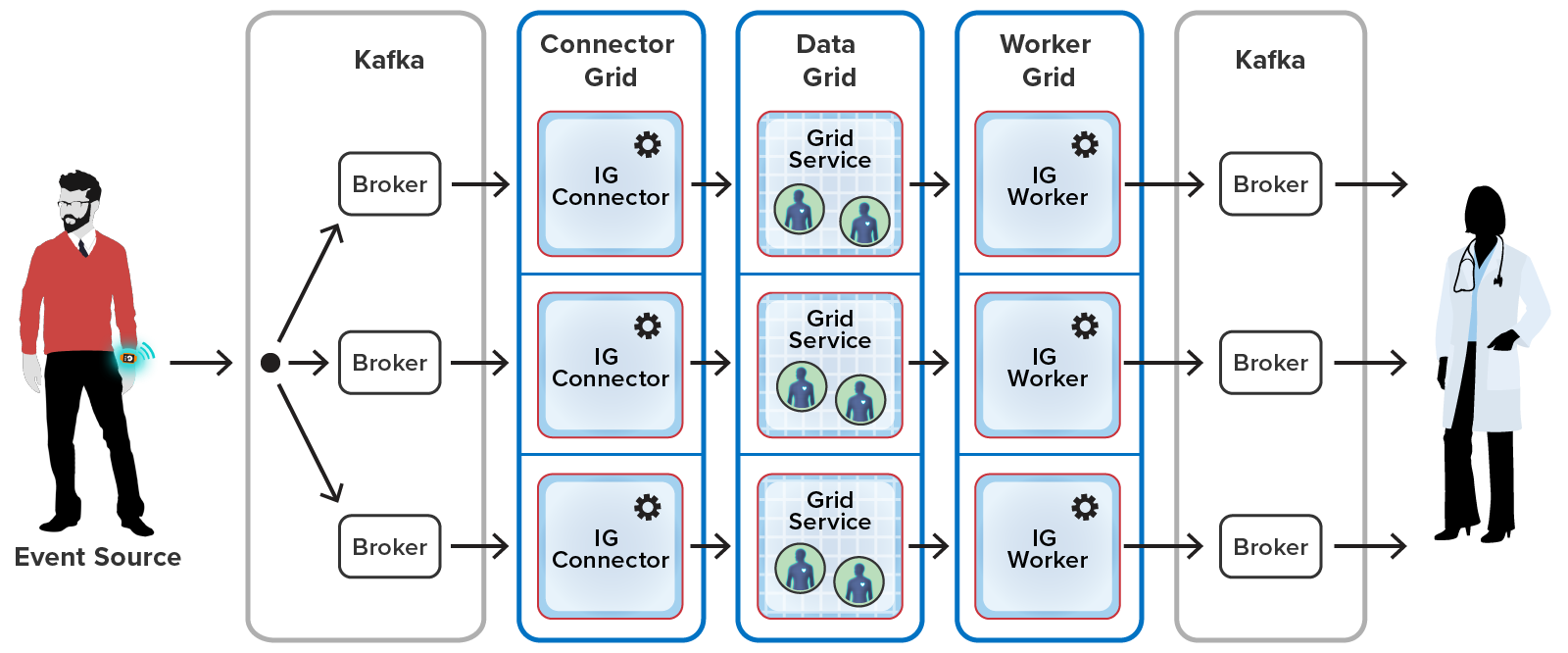
Illustration of Stateful Stream-Processing for a Medical Monitoring Application
Wide Range of Applications
Stateful stream-processing with digital twins can dramatically improve the quality of real-time feedback for virtually any stream processing application. Here are just a few examples:
- Vehicle telematics: tracking fleets of vehicles, drivers, and cargo to quickly detect emerging issues and help ensure timely deliveries
- Safety and security monitoring: tracking physical and cyber sensors, as well as badged personnel, to detect and react to intrusions and/or unsafe operations
- Financial services: portfolio tracking, wire fraud detection, stock back-testing, usage-based insurance
- Internet of Things (IoT): device tracking for manufacturing, vehicles, fixed and mobile devices, and smart cities
- Healthcare: real-time patient monitoring, medical device tracking and alerting
- Logistics: real-time inventory reconciliation, manufacturing flow optimization
Digital Twin Builder
The ScaleOut Digital Twin Builder™ software toolkit dramatically simplifies the development of Java, C#, JavaScript, and rules-based real-time digital twin models and their deployment on ScaleOut StreamServer. These application-defined models specify the properties and message-processing code required to track dynamic state information for each data source and analyze its incoming events with a richer context than previously possible. This leads to deeper real-time introspection and better feedback and alerting.
For example, using the real-time digital twin model, a rental car company can track and analyze telemetry from each car in its fleet with digital twins that have detailed knowledge about each car’s rental contract, the driver’s demographics and driving record, and maintenance issues. With this information the application could, for example, alert managers when a driver repeatedly exceeds the speed limit according to criteria specific to the driver’s age and driving history or violates other terms of the rental contract. All of this leads to new insights on telemetry received from vehicles that otherwise would not be available in real time:
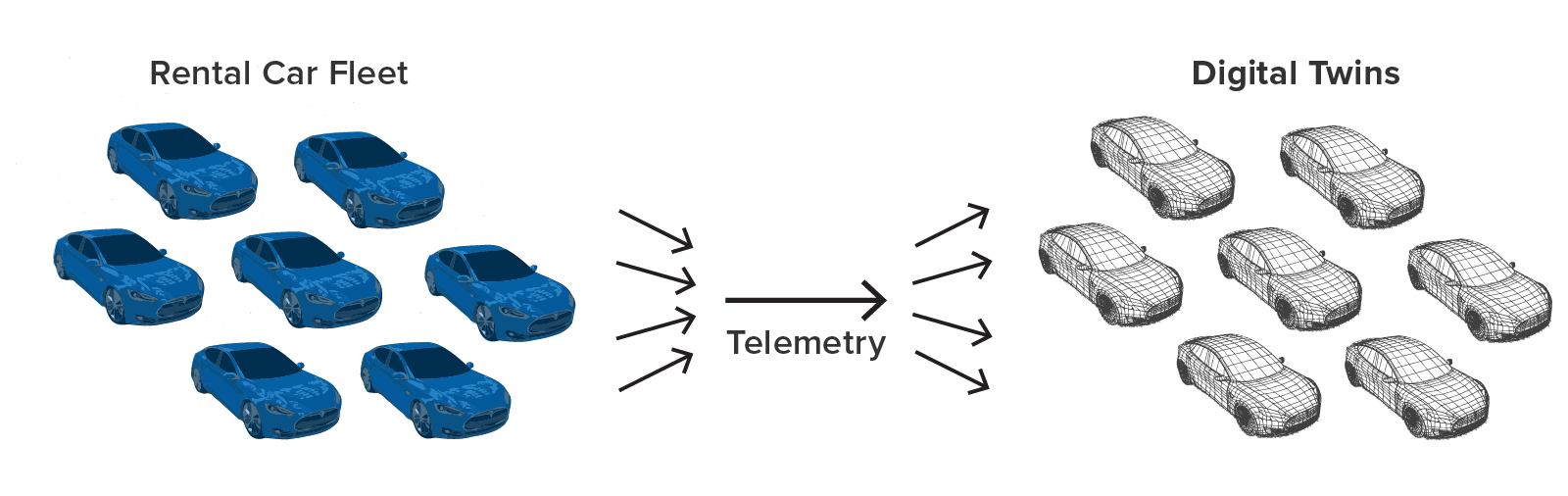
By tracking the state of data sources, digital twin models add value in almost every imaginable stream-processing application. They enable real-time streaming analytics that previously could only be performed in offline, batch processing. Here are a few examples:
- They help IoT applications do a better job of predictive analytics when processing event messages by tracking the parameters of each device, when maintenance was last performed, known anomalies, and much more.
- They assist healthcare applications in interpreting real-time telemetry, such as blood-pressure and heart-rate readings, in the context of each patient’s medical history, medications, and recent incidents, so that more effective alerts can be generated when care is needed.
- They enable ecommerce applications to interpret website clickstreams with the knowledge of each shopper’s demographics, brand preferences, and recent purchases to make more targeted product recommendations.
Check out how the ScaleOut Digital Twin Builder delivers breakthrough capabilities for stateful stream-processing here.
A Unified Architecture for Stateful Stream-Processing
By integrating a fast, scalable stream-processing engine with an in-memory data grid, ScaleOut Software has created a unified software platform for the next-generation of stream processing. Unlike mainstream platforms such as Apache Flink, Spark, and Storm, ScaleOut StreamServer enables applications to implement object-oriented models of data sources. It can host large populations of data objects in memory on a cluster of commodity servers and dispatch incoming streaming events to these objects for analysis. Applications now can process incoming data streams in a rich context of evolving state, enabling the use of sophisticated algorithms while delivering blazingly fast event handling.
ScaleOut StreamServer’s innovative architecture delivers both breakthrough capabilities and peak performance for stateful stream processing. It processes incoming data streams within an in-memory data grid — where the data lives — ensuring minimum latency and peak throughput. Other platforms need to pull state information from remote data stores, such as database servers and distributed caches; this creates delays and network bottlenecks.
Instead, ScaleOut StreamServer delivers streamed events directly to their associated state data, enabling immediate, fully contextual processing. Its transparently scalable platform minimizes the latency required for event tracking and analysis, ensuring timely feedback and/or alerts for the largest workloads.
Integrated Streaming & Batch
ScaleOut StreamServer’s integration of an in-memory data grid and compute engine enables it to simultaneously perform both stream-processing and data-parallel analysis on grid-based data. This means that while digital twin objects are processing incoming events, MapReduce (and other data-parallel techniques) can analyze and report aggregate patterns and trends.
Fast, Scalable, and Highly Available
ScaleOut StreamServer employs a unified, fully distributed architecture that transparently scales across commodity servers or cloud instances to increase throughput as needed. This enables the platform to handle large workloads and ensure fast event processing. The grid’s integrated high availability keeps mission-critical data safe at all times.
Unique Advantages for Streaming Data
Traditional CEP and stream processing platforms, such as Apache Flink and Spark Streaming, focus on analyzing incoming data streams without regard to the context in which the data was created. The next generation of stream-processing tracks the dynamic state of data sources as “digital twins,” offering a basis for much deeper introspection and more effective alerting. ScaleOut StreamServer’s unique architecture, which executes streaming operations within an in-memory data grid, creates a breakthrough that enables stateful stream-processing with digital twin models.