Traditional stream-processing and complex event processing systems, such as Apache Storm and Software AG’s Apama, have focused on extracting interesting patterns from incoming data with stateless applications. While these applications maintain state information about the data stream itself, they don’t generally make use of information about the data sources or their context. For example, if an IoT application is attempting to detect whether data from a temperature sensor is predicting the failure of the medical freezer to which it is attached, it looks at patterns in the temperature changes, such as sudden spikes or a continuously upward trend, without regard to the freezer’s usage or service history.
The following diagram depicts a typical stream processing pipeline processing events from many data sources:
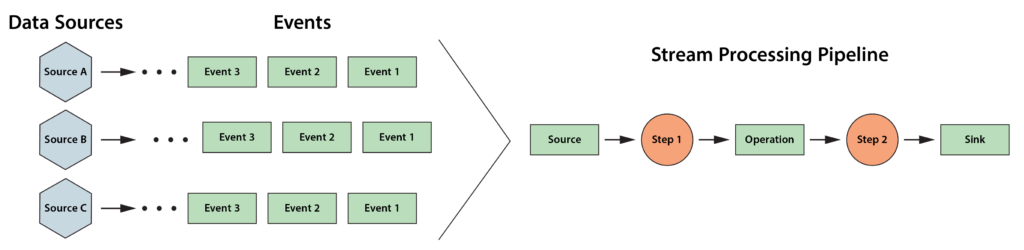
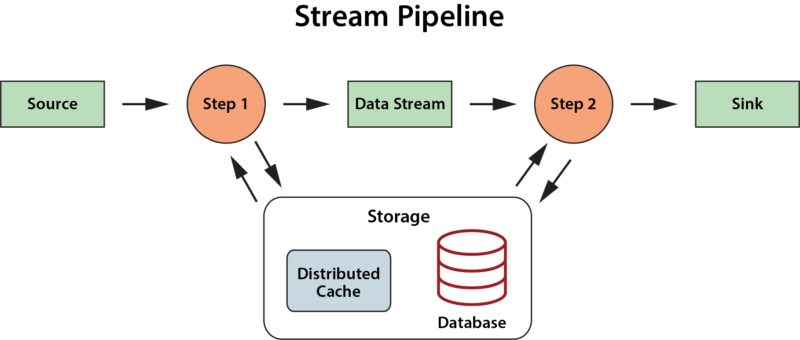
More recent stream-processing platforms, such as Apache Flink, have incorporated stateful stream processing into their architectures in the form of key-value stores or databases that the application can make use of to enhance its analysis. But they do not offer a specific semantic model which applications can leverage to organize and track useful state information and thereby deepen their ability to analyze data streams.
The answer to this challenge may be found in the digital twin model. While this term was coined by Dr. Michael Grieves (U. Michigan) in 2002 for use in product life cycle management, it was recently popularized for IoT by Gartner in a 2017 report. This model offers key insights into how state data can be organized within stream-processing applications for maximum effectiveness. In particular, it suggests that applications implement a stateful model of the physical data sources that generate event streams, and that the application maintain separate state information for each data source. For example, using the digital twin model, a rental car company can track and analyze telemetry from each car in its fleet with digital twins:
The digital twin model thereby provides an intuitive approach to organizing state data, and, by shifting the focus of analysis from the event stream to the data sources, it potentially enables much deeper introspection than previously possible. With the digital twin model, an application can conveniently track all relevant information about the evolving state of physical data sources. It can then analyze incoming events in this rich context to provide high quality insights, alerting, and feedback. For example, digital twins of medical freezers could track detailed facts about the specific model, its service history, environmental conditions, and usage patterns for each physical unit to help analyze telemetry from a temperature sensor and make more informed predictions about possible impending failures.
Beyond providing a powerful semantic model for stateful stream processing, digital twins also offer advantages for software engineering because they can take advantage of well understood object-oriented programming techniques. A digital twin can be implemented as a data class which encapsulates both state data (including a time-ordered event collection) and methods for updating and analyzing that data. Analytics methods can range from simple sequential code to machine learning algorithms or rules engines. These methods also can reach out to databases to access and update historical data sets.
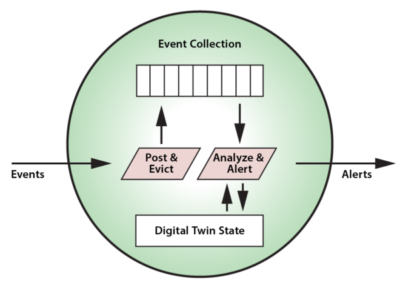
For each physical data source, an instance of a digital twin model is created by the stream-processing system to receive and analyze events. It is the responsibility of the system to correlate data from a given data source for delivery to each instance of a physical twin. In many applications, a stream-processing system may host thousands (or more) digital twins to handle the workload from its data sources. In an upcoming blog, we will look at how in-memory data grids provide a highly scalable platform for hosting digital twins.
One parting thought concerns the granularity of a digital twin. Does it encompass a model of a single sensor or that of a subsystem comprising multiple sensors? As with object-oriented programming in general, the answer is in the hands of the application developer, who must make choices about which data (and event streams) are logically related and need to be encapsulated in a single entity for analysis to meet the application’s goals.
The digital twin model provides a powerful organizational tool that focuses on the state of data sources instead of just the data within event streams. With this additional context, it magnifies the developer’s ability to implement deep introspection and represents a new way of thinking about stateful stream processing.